
如何设置硬件加速选项:GPU/DC/MPI/token
经常有用户问如何设置硬件加速的问题,这里我们解释一下Acceleration加速界面。
1)默认
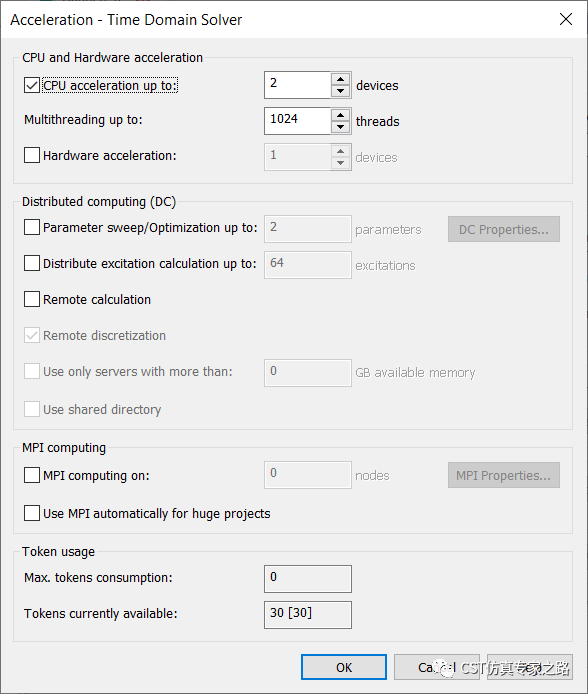
默认基本上什么都没选,CPU免费使用两个,不是两个核,是两个CPU。
2)使用GPU
如果本地电脑有GPU,可以选上Hardware acceleration使用GPU加速,比如两张GPU这样设定。这就需要消耗加速token,界面下方预告这样设置消耗的token数量为两个,我的许可有30个token可以用,括号内显示购买的30不会变。括号外(前面)的30是可用的token数量,可以变少,如果其他同事分享使用,有仿真正在运行,则可以占据一定数量。所以预告的使用token数量不能比可用的数量多哦。

3) 分布式计算
比如下图,这样设置是假设我们有三台机器同时运算,每个计算一个端口激励。同时GPU也有选2个,所以是假设每个机器上面都用两个GPU。可见这样的仿真任务消耗6个token。同理,参数扫描过程中,每个参数也可以分配到各个机器上。
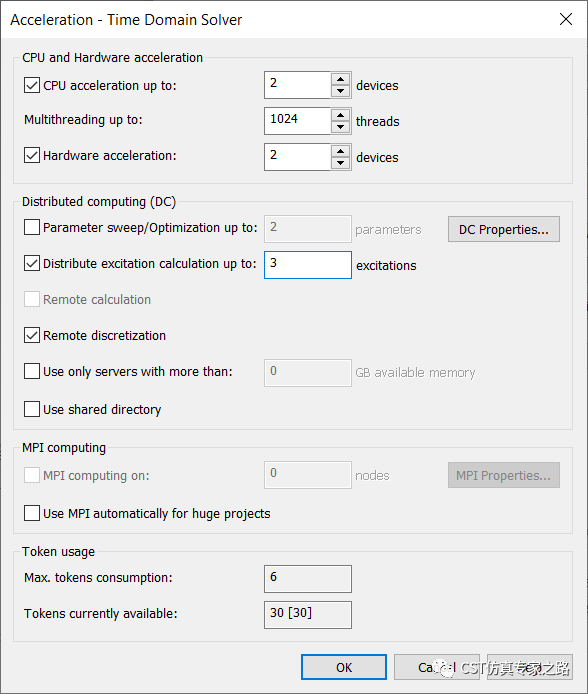
这里可以设置分布式的硬件,默认采取全局的Main Controller设置。Main Controller 可以是本机器,也可以其他机器(不动的工作站最好)。全局设置是随CST安装的Main Controller Administration程序中设定,可设置使用的机器,以及不同机器的优先级等等具体的信息,用户提交自动根据这些设置选择机器。如使用Use specified DC solver servers选项,则可通过Connected DC solver servers, 手动选择我们希望使用的机器。

3) 远程计算
可单选remote calculation将该仿真任务用远程的一台机器计算,不消耗token。远程计算机也要安装同版本CST,有许可。
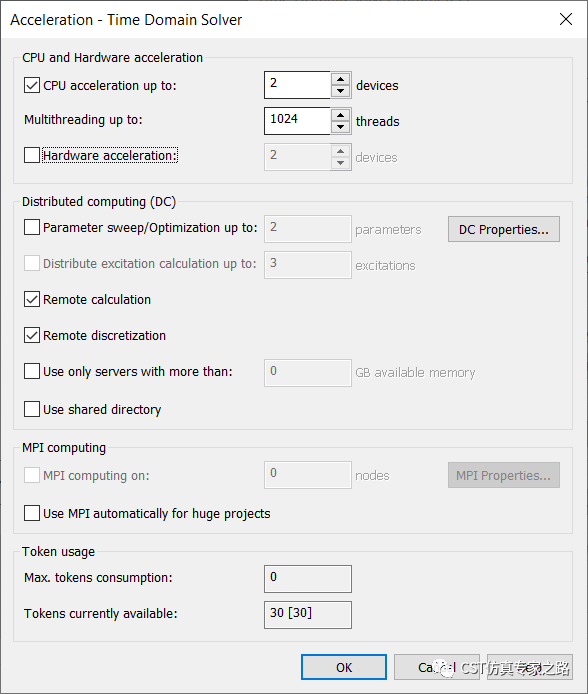
4)如有MPI配置,同理在MPI处设置。对于无MPI配置的用户本地计算大模型,若网格大过2Billion(20个小目标),可选Use MPI automatically for huge projects, 则本地自动MPI分解计算模型。不消耗token。
最后,提交仿真任务不要马上离开,养成观察Message和log的习惯哦!




