
CST中如何使用分布式计算进行参数扫描
作者 | Wang Yuanteng
我们知道,分布式计算非常适合进行参数扫描、优化这种互相独立的任务。之前我们介绍了,FAQ117:如何安装和设置分布式计算?
但不少用户对参数扫描的设置仍有疑惑,下面我们将详细介绍设置方法。
1:参扫选项。以时域求解器设置界面为例,在solver->Acceleration->DC,勾选Parameter sweep,输入同时扫描的参数数量,该值直接影响下方token所需数量。

DC properties设置:
这里可以选择use global setting,也就是所用solver server跟main controller中所设一致,main controller可以修改(Change global settings…),指向不同的main controller机器。
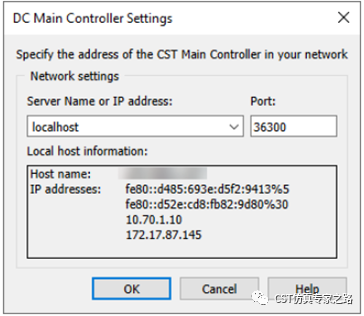
这两个界面都有Loacl host information供参考。
或者我们可以点击Use specified DC solver server去指定要使用的solver server。
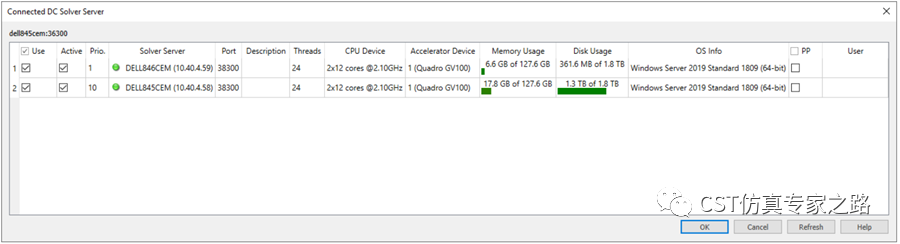
2. 了解基本设置后,我们来说明下所需token数量。DC参数数量(N)指在多个solver server上同时进行计算的job数量,一般来说,应设为小于等于总的server数量,那么所消耗的token数为N个节点CPU和GPU所需token的总和,在设置界面下方token
usage给出显示。
当所设参数数量大于实际solver数量时,界面上所显示的token数由参数数量N计算得到,但实际同时计算的参数和对应消耗的token由solver server数量决定,所以这么做不利于直接看所需token数量。
验证一下:
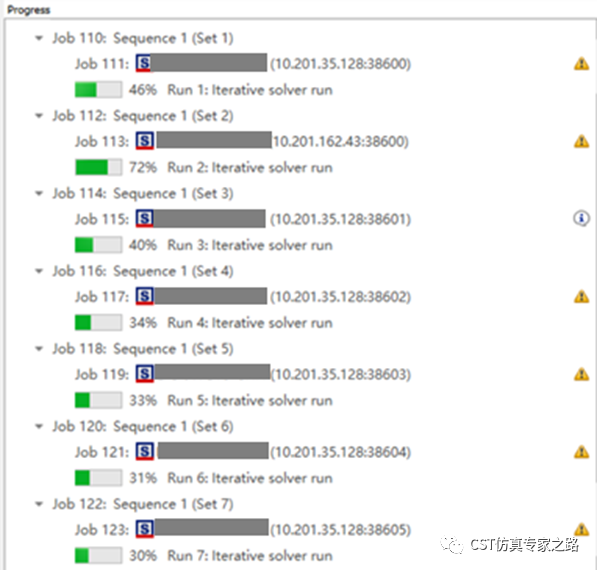
条件所限,这里将两台电脑分成多个节点进行计算,PC1有6个节点,PC2有2个节点,共8个节点,设成8个参数。

从progress可以看到,任务被分配到2台电脑的8个节点上进行计算。
从Main control可以看到全部节点都在running job。
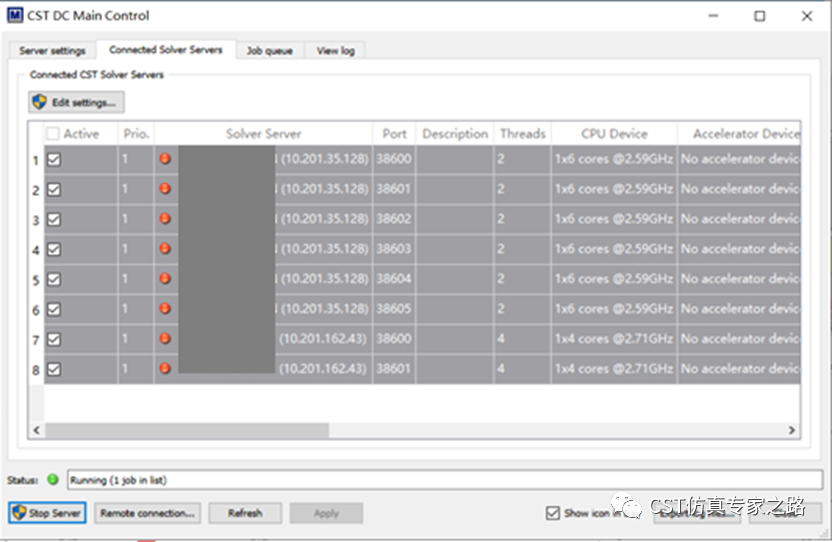
如前面求解器界面显示,使用了 2个S2T。
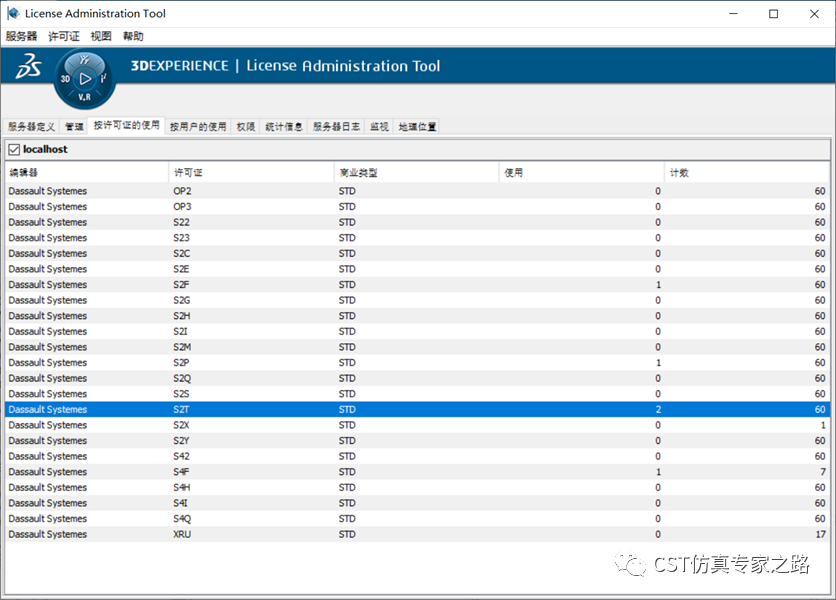
虽然这种情况下,两台电脑实际只有2颗CPU,但在8个server同时跑了8个job,每个server设为1个CPU,那么总共使用了8个CPU,按此计算得到token数量。有点用S2T换S2P的意思。
3. 最后一个问题,假如有80个参数,但只有8个server,DC参数设为8,那会怎么样呢?Main
Controller会分批处理这80个job,如下在progess看到waiting和pending状态。





