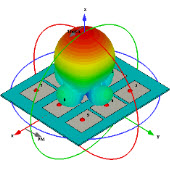
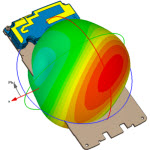
CST MWS仿真大型阵列天线跑不动的问题
我现在用的机子是我好不容易才弄来的一台服务器,12个核24线程的CPU,16G内存,目前经过我长期测试,能够跑3亿以下的网格,超过3亿就会死机,但是即使我使用了对称面并将网格划分到2亿8千万,也是个不精确的结果。在网格特性(mesh cells proporties)的三个选项中分别是8,8,8。我曾用一个小型的阵列天线试过,将网格划分到(8,8,8)增益为19dB,而将网格划分到(15,15,15)之后增益能达到25dB,其余所有设置都一样。我想向各位大侠请教一下这种情况有么有什么好的解决方法?
最后补充说明一下,我用的是CST2012
Hardware Acceleration
可以试试用矩量法求解器,对于金属使用表面网格,而且有快速多级子加速,没准比时域要快。
或者用SBR方法
组合仿真技术SAM可以用的上么
小编你要仿真多大的天线阵呢?
理论上16G内存的电脑只能仿真1亿6千万的网格,看来你的虚拟内存比较大。
网格设置8 8 8已经不准确了,一般估算都要求设置在10以上,10以下的结果没有参考价值
如果实在不行可以尝试MPI。
硬件加速我尝试过,用普通的Geforce显卡,加速效果几乎可以忽略。人家CST公司给的GPU加速的说明文档上例举的那几个加速卡…………买不起
您说的这个我都没听说过,怎么个用法?求指教
如何操作能说得更具体些吗?
传模型上来,给你试试。
MPI是?
还有请教一下作为八级大师的您,论坛里说的局部加密网格的方法这里是否可行,如果可行,该如何操作?谢谢
Geforce哪儿来的加速效果?只有Quadro 5800/Tesla 10以上系列才是加速卡。
额,我们单位同事那些搞计算机的,都是拿的两三千的Geforce显卡在弄加速,据说效果还不错,所以我才拿Geforce的显卡试试的。
MPI是集群计算,局部网格加密只会越加越密。
高性能计算没有Geforce什么事情,专业卡做专业的事情,商业卡做商业的事情。
16G有点小吧,都12个 core了,加内存吧
请问小编有多少个element? 激励是什么样的?可以只仿真部分elements再进行叠加吗?
Tesla系列和最新的K系列才能做加速,两三千的Geforce还是歇了吧。
每个单元是不一样的,所以不能仿部分,然后叠加
我的意思是只把面板上那一块用比较密的仿,如(15,15,15),其余的空间部分改小,如(10,10,10)不知道可不可行?
官方刚出的技术,我也不熟悉,看了官方的宣传视频才知道的
没有验证过不知道。
网格剖分低于10靠谱么
已验证,不靠谱!
相关文章:
- CST仿真微带阵列天线 (05-08)
- CST仿真阵列天线的互耦问题 (05-08)
- CST仿真阵列天线馈电问题 (05-08)
- 用CST仿真微带反射阵列天线单元时,在ground上加缝隙时边界条件怎么设置? (05-08)
- 大型阵列天线远场方向图合成 (05-08)
- cst仿真错误提示,请求帮助 (05-08)